1.无锁化
加锁是为了避免在并发环境下,同时访问共享资源产生的安全问题。那么,在并发环境下,是否必须加锁?答案是否定的。并非所有的并发都需要加锁。适当地降低锁的粒度,甚至采用无锁化的设计,更能提升并发能力。
无锁化主要有两种实现,无锁数据结构和串行无锁。
1.1 无锁数据结构
利用硬件支持的原子操作可以实现无锁的数据结构,原子操作可以在 lock-free 的情况下保证并发安全,并且它的性能也能做到随 CPU 个数的增多而线性扩展。很多语言都提供 CAS 原子操作(如 Go 中的 atomic 包和 C++11 中的 atomic 库),可以用于实现无锁数据结构,如无锁链表。
我们以一个简单的线程安全单向链表的插入操作来看下无锁编程和普通加锁的区别。
package list
import (
"fmt"
"sync"
"sync/atomic"
"golang.org/x/sync/errgroup"
)
// Node 链表结点。
type Node struct {
Value interface{}
Next *Node
}
//
// 有锁单向链表的简单实现。
//
// WithLockList 有锁单向链表。
type WithLockList struct {
Head *Node
mu sync.Mutex
}
// Push 无锁单向链表插入。
func (l *WithLockList) Push(v interface{}) {
l.mu.Lock()
defer l.mu.Unlock()
n := &Node{
Value: v,
Next: l.Head,
}
l.Head = n
}
// String 有锁链表的字符串形式输出。
func (l WithLockList) String() string {
s := ""
cur := l.Head
for {
if cur == nil {
break
}
if s != "" {
s += ","
}
s += fmt.Sprintf("%v", cur.Value)
cur = cur.Next
}
return s
}
//
// 无锁单向链表的简单实现。
//
// LockFreeList 无锁单向链表。
type LockFreeList struct {
Head atomic.Value
}
// Push 有锁单向链表插入。
func (l *LockFreeList) Push(v interface{}) {
for {
head := l.Head.Load()
headNode, _ := head.(*Node)
n := &Node{
Value: v,
Next: headNode,
}
if l.Head.CompareAndSwap(head, n) {
break
}
}
}
// String 无锁链表的字符串形式输出。
func (l LockFreeList) String() string {
s := ""
cur := l.Head.Load().(*Node)
for {
if cur == nil {
break
}
if s != "" {
s += ","
}
s += fmt.Sprintf("%v", cur.Value)
cur = cur.Next
}
return s
}
上面的实现有几点需要注意一下:
(1)无锁单向链表实现时在插入时需要进行 CAS 操作,即调用CompareAndSwap()方法进行插入,如果插入失败则进行 for 循环多次尝试,直至成功。
(2)为了方便打印链表内容,实现一个String()方法遍历链表,且使用值作为接收者,避免打印对象指针时无法生效。
- If an operand implements method String() string, that method will be invoked to convert the object to a string, which will then be formatted as required by the verb (if any).
我们分别对两种链表做一个并发写入的操作验证一下其功能。
package main
import (
"fmt"
"main/list"
)
// ConcurWriteWithLockList 并发写入有锁链表。
func ConcurWriteWithLockList(l *WithLockList) {
var g errgroup.Group
// 10 个协程并发写入链表
for i := 0; i < 10; i++ {
i := i
g.Go(func() error {
l.Push(i)
return nil
})
}
_ = g.Wait()
}
// ConcurWriteLockFreeList 并发写入无锁链表。
func ConcurWriteLockFreeList(l *LockFreeList) {
var g errgroup.Group
// 10 个协程并发写入链表
for i := 0; i < 10; i++ {
i := i
g.Go(func() error {
l.Push(i)
return nil
})
}
_ = g.Wait()
}
func main() {
// 并发写入与遍历打印有锁链表。
l1 := &list.WithLockList{}
list.ConcurWriteWithLockList(l1)
fmt.Println(l1)
// 并发写入与遍历打印无锁链表。
l2 := &list.LockFreeList{}
list.ConcurWriteLockFreeList(l2)
fmt.Println(l2)
}
注意,多次运行上面的main()函数的结果可能会不相同,因为并发是无序的。
8,7,6,9,5,4,3,1,2,0
9,8,7,6,5,4,3,2,0,1
下面再看一下链表 Push 操作的基准测试,对比一下有锁与无锁的性能差异。
func BenchmarkWriteWithLockList(b *testing.B) {
l := &WithLockList{}
for n := 0; n < b.N; n++ {
l.Push(n)
}
}
BenchmarkWriteWithLockList-8 14234166 83.58 ns/op
func BenchmarkWriteLockFreeList(b *testing.B) {
l := &LockFreeList{}
for n := 0; n < b.N; n++ {
l.Push(n)
}
}
BenchmarkWriteLockFreeList-8 15219405 73.15 ns/op
可以看出无锁版本比有锁版本性能高一些。
1.2 串行无锁
串行无锁是一种思想,就是避免对共享资源的并发访问,改为每个并发操作访问自己独占的资源,达到串行访问资源的效果,来避免使用锁。不同的场景有不同的实现方式。比如网络 I/O 场景下将单 Reactor 多线程模型改为主从 Reactor 多线程模型,避免对同一个消息队列锁读取。
这里我介绍的是后台微服务开发经常遇到的一种情况。我们经常需要并发拉取多方面的信息,汇聚到一个变量上。那么此时就存在对同一个变量互斥写入的情况。比如批量并发拉取用户信息写入到一个 map。此时我们可以将每个协程拉取的结果写入到一个临时对象,这样便将并发地协程与同一个变量解绑,然后再将其汇聚到一起,这样便可以不用使用锁。即独立处理,然后合并。
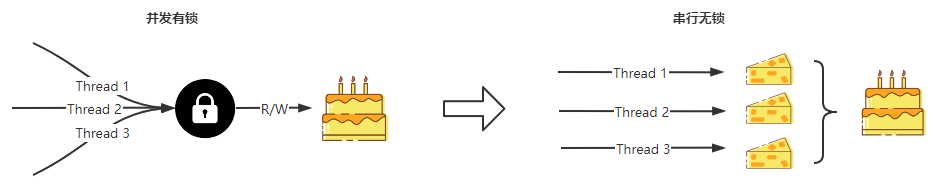
为了模拟上面的情况,简单地写个示例程序,对比下性能。
import (
"sync"
"golang.org/x/sync/errgroup"
)
// ConcurWriteMapWithLock 有锁并发写入 map
func ConcurWriteMapWithLock() map[int]int {
m := make(map[int]int)
var mu sync.Mutex
var g errgroup.Group
// 10 个协程并发写入 map
for i := 0; i < 10; i++ {
i := i
g.Go(func() error {
mu.Lock()
defer mu.Unlock()
m[i] = i * i
return nil
})
}
_ = g.Wait()
return m
}
// ConcurWriteMapLockFree 无锁并发写入 map
func ConcurWriteMapLockFree() map[int]int {
m := make(map[int]int)
// 每个协程独占一 value
values := make([]int, 10)
// 10 个协程并发写入 map
var g errgroup.Group
for i := 0; i < 10; i++ {
i := i
g.Go(func() error {
values[i] = i * i
return nil
})
}
_ = g.Wait()
// 汇聚结果到 map
for i, v := range values {
m[i] = v
}
return m
}
看下二者的性能差异:
func BenchmarkConcurWriteMapWithLock(b *testing.B) {
for n := 0; n < b.N; n++ {
_ = ConcurWriteMapWithLock()
}
}
BenchmarkConcurWriteMapWithLock-8 218673 5089 ns/op
func BenchmarkConcurWriteMapLockFree(b *testing.B) {
for n := 0; n < b.N; n++ {
_ = ConcurWriteMapLockFree()
}
}
BenchmarkConcurWriteMapLockFree-8 316635 4048 ns/op
2.减少锁竞争
如果加锁无法避免,则可以采用分片的形式,减少对资源加锁的次数,这样也可以提高整体的性能。
比如 Golang 优秀的本地缓存组件 bigcache 、go-cache、freecache 都实现了分片功能,每个分片一把锁,采用分片存储的方式减少加锁的次数从而提高整体性能。
以一个简单的示例,通过对map[uint64]struct{}分片前后并发写入的对比,来看下减少锁竞争带来的性能提升。
var (
num = 1000000
m0 = make(map[int]struct{}, num)
mu0 = sync.RWMutex{}
m1 = make(map[int]struct{}, num)
mu1 = sync.RWMutex{}
)
// ConWriteMapNoShard 不分片写入一个 map。
func ConWriteMapNoShard() {
g := errgroup.Group{}
for i := 0; i < num; i++ {
g.Go(func() error {
mu0.Lock()
defer mu0.Unlock()
m0[i] = struct{}{}
return nil
})
}
_ = g.Wait()
}
// ConWriteMapTwoShard 分片写入两个 map。
func ConWriteMapTwoShard() {
g := errgroup.Group{}
for i := 0; i < num; i++ {
g.Go(func() error {
if i&1 == 0 {
mu0.Lock()
defer mu0.Unlock()
m0[i] = struct{}{}
return nil
}
mu1.Lock()
defer mu1.Unlock()
m1[i] = struct{}{}
return nil
})
}
_ = g.Wait()
}
看下二者的性能差异。
func BenchmarkConWriteMapNoShard(b *testing.B) {
for i := 0; i < b.N; i++ {
ConWriteMapNoShard()
}
}
BenchmarkConWriteMapNoShard-12 3 472063245 ns/op
func BenchmarkConWriteMapTwoShard(b *testing.B) {
for i := 0; i < b.N; i++ {
ConWriteMapTwoShard()
}
}
BenchmarkConWriteMapTwoShard-12 4 310588155 ns/op
可以看到,通过对分共享资源的分片处理,减少了锁竞争,能明显地提高程序的并发性能。可以预见的是,随着分片粒度地变小,性能差距会越来越大。当然,分片粒度不是越小越好。因为每一个分片都要配一把锁,那么会带来很多额外的不必要的开销。可以选择一个不太大的值,在性能和花销上寻找一个平衡。
3.优先使用共享锁而非互斥锁
如果并发无法做到无锁化,优先使用共享锁而非互斥锁。
所谓互斥锁,指锁只能被一个 Goroutine 获得。共享锁指可以同时被多个 Goroutine 获得的锁。
Go 标准库 sync 提供了两种锁,互斥锁(sync.Mutex)和读写锁(sync.RWMutex),读写锁便是共享锁的一种具体实现。
3.1 sync.Mutex
互斥锁的作用是保证共享资源同一时刻只能被一个 Goroutine 占用,一个 Goroutine 占用了,其他的 Goroutine 则阻塞等待。
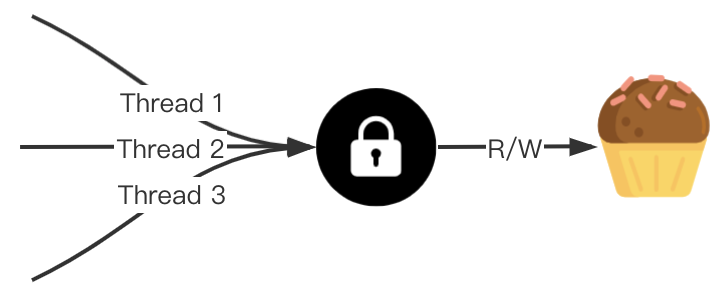
sync.Mutex 提供了两个导出方法用来使用锁。
Lock() // 加锁
Unlock() // 释放锁
我们可以通过在访问共享资源前前用 Lock 方法对资源进行上锁,在访问共享资源后调用 Unlock 方法来释放锁,也可以用 defer 语句来保证互斥锁一定会被解锁。在一个 Go 协程调用 Lock 方法获得锁后,其他请求锁的协程都会阻塞在 Lock 方法,直到锁被释放。
3.2 sync.RWMutex
读写锁是一种共享锁,也称之为多读单写锁 (multiple readers, single writer lock)。在使用锁时,对获取锁的目的操作做了区分,一种是读操作,一种是写操作。因为同一时刻允许多个 Gorouine 获取读锁,所以是一种共享锁。但写锁是互斥的。
一般来说,有如下几种情况:
- 读锁之间不互斥,没有写锁的情况下,读锁是无阻塞的,多个协程可以同时获得读锁。
- 写锁之间是互斥的,存在写锁,其他写锁阻塞。
- 写锁与读锁是互斥的,如果存在读锁,写锁阻塞,如果存在写锁,读锁阻塞。
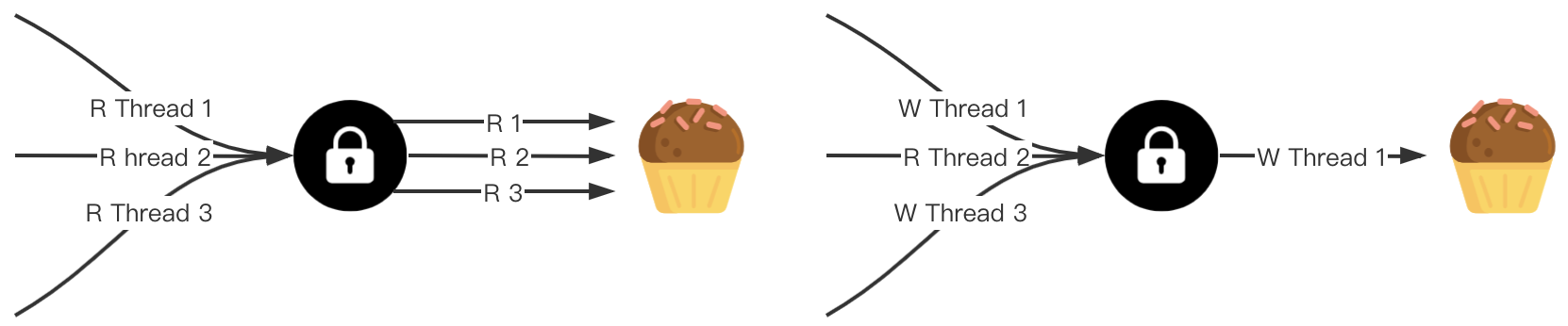
sync.RWMutex 提供了五个导出方法用来使用锁。
Lock() // 加写锁
Unlock() // 释放写锁
RLock() // 加读锁
RUnlock() // 释放读锁
RLocker() Locker // 返回读锁,使用 Lock() 和 Unlock() 进行 RLock() 和 RUnlock()
读写锁的存在是为了解决读多写少时的性能问题,读场景较多时,读写锁可有效地减少锁阻塞的时间。
3.3 性能对比
大部分业务场景是读多写少,所以使用读写锁可有效提高对共享数据的访问效率。最坏的情况,只有写请求,那么读写锁顶多退化成互斥锁。所以优先使用读写锁而非互斥锁,可以提高程序的并发性能。
接下来,我们测试三种情景下,互斥锁和读写锁的性能差异。
- 读多写少(读占 80%)
- 读写一致(各占 50%)
- 读少写多(读占 20%)
首先根据互斥锁和读写锁分别实现对共享 map 的并发读写。
// OpMapWithMutex 使用互斥锁读写 map。
// rpct 为读操作占比。
func OpMapWithMutex(rpct int) {
m := make(map[int]struct{})
mu := sync.Mutex{}
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
i := i
wg.Add(1)
go func() {
defer wg.Done()
mu.Lock()
defer mu.Unlock()
// 写操作。
if i >= rpct {
m[i] = struct{}{}
time.Sleep(time.Microsecond)
return
}
// 读操作。
_ = m[i]
time.Sleep(time.Microsecond)
}()
}
wg.Wait()
}
// OpMapWithRWMutex 使用读写锁读写 map。
// rpct 为读操作占比。
func OpMapWithRWMutex(rpct int) {
m := make(map[int]struct{})
mu := sync.RWMutex{}
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
i := i
wg.Add(1)
go func() {
defer wg.Done()
// 写操作。
if i >= rpct {
mu.Lock()
defer mu.Unlock()
m[i] = struct{}{}
time.Sleep(time.Microsecond)
return
}
// 读操作。
mu.RLock()
defer mu.RUnlock()
_ = m[i]
time.Sleep(time.Microsecond)
}()
}
wg.Wait()
}
入参 rpct 用来调节读操作的占比,来模拟读写占比不同的场景。rpct 设为 80 表示读多写少(读占 80%),rpct 设为 50 表示读写一致(各占 50%),rpct 设为 20 表示读少写多(读占 20%)。
func BenchmarkMutexReadMore(b *testing.B) {
for i := 0; i < b.N; i++ {
OpMapWithMutex(80)
}
}
func BenchmarkRWMutexReadMore(b *testing.B) {
for i := 0; i < b.N; i++ {
OpMapWithRWMutex(80)
}
}
func BenchmarkMutexRWEqual(b *testing.B) {
for i := 0; i < b.N; i++ {
OpMapWithMutex(50)
}
}
func BenchmarkRWMutexRWEqual(b *testing.B) {
for i := 0; i < b.N; i++ {
OpMapWithRWMutex(50)
}
}
func BenchmarkMutexWriteMore(b *testing.B) {
for i := 0; i < b.N; i++ {
OpMapWithMutex(20)
}
}
func BenchmarkRWMutexWriteMore(b *testing.B) {
for i := 0; i < b.N; i++ {
OpMapWithRWMutex(20)
}
}
执行当前包下的所有基准测试,结果如下:
dablelv@DABLELV-MB0 mutex % go test -bench=.
goos: darwin
goarch: amd64
pkg: main/mutex
cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
BenchmarkMutexReadMore-12 2462 485917 ns/op
BenchmarkRWMutexReadMore-12 8074 145690 ns/op
BenchmarkMutexRWEqual-12 2406 498673 ns/op
BenchmarkRWMutexRWEqual-12 4124 303693 ns/op
BenchmarkMutexWriteMore-12 1906 532350 ns/op
BenchmarkRWMutexWriteMore-12 2462 432386 ns/op
PASS
ok main/mutex 9.532s
可见读多写少的场景,使用读写锁并发性能会更优。可以预见的是如果写占比更低,那么读写锁带的并发效果会更优。
这里需要注意的是,因为每次读写 map 的操作耗时很短,所以每次睡眠一微秒(百万分之一秒)来增加耗时,不然对共享资源的访问耗时,小于锁处理的本身耗时,那么使用读写锁带来的性能优化效果将变得不那么明显,甚至会降低性能。