# 1.简介
联合索引指建立在多个列上的索引。
MySQL 可以创建联合索引(即多列上的索引)。一个索引最多可以包含 16 列。
联合索引可以测试包含索引中所有列的查询,或仅测试第一列、前两列、前三列等等的查询。如果在索引定义中以正确的顺序指定列,则复合索引可以加快对同一表的多种查询的速度。
下面是一个联合索引的例子。
CREATE TABLE test (
id INT NOT NULL,
last_name CHAR(30) NOT NULL,
first_name CHAR(30) NOT NULL,
PRIMARY KEY (id),
INDEX name (last_name,first_name)
);
name 索引是针对 last_name 和 first_name 列的索引。该索引可加速查询。这些查询为 last_name 和 first_name 值的组合。或仅指定 last_name 值的查询,因为该列是索引的最左侧前缀,即联合索引支持最左匹配。
# 2.最左匹配
如果 SQL 语句用到了联合索引中最左边的字段,那么这条 SQL 语句就可以利用这个联合索引进行匹配,这便是最左匹配。
值得注意的是,当遇到范围查询 (>、<、between、like) 就会停止匹配。
假设,我们对 (a,b) 字段建立一个索引,也就是说,如果 WHERE 条件为下面的则可以匹配索引。
a = 1
a = 1 AND b = 2
// 可以匹配索引,优化器会自动调整 a,b 的顺序与索引顺序一致。
b = 2 AND a = 1
相反的,下面的条件将无法匹配索引了。
b = 2
而你对 (a,b,c,d) 建立索引,如果条件为:
a = 1 AND b = 2 AND c > 3 AND d = 4
那么 a,b,c 三个字段能用到索引,而 d 就匹配不到,因为遇到了范围查询。
# 3.最左匹配原理
最左匹配是针对联合索引来说的,所以我们可以从联合索引的原理来了解最左匹配。
我们都知道索引的底层是一颗 B+ 树,那么联合索引当然也是一颗 B+ 树,只不过联合索引的键值不是一个,而是多个。构建一颗 B+ 树只能根据一个键值来构建,因此数据库依据联合索引最左边的字段来构建 B+ 树。
假设我们对 (a,b) 字段建立索引:
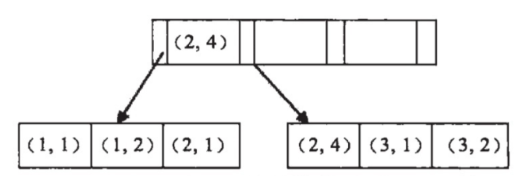
如图所示是按照 a 来进行排序,在 a 相等的情况下,才按 b 来排序。
所以这就能够解释为什么条件 a=1 AND b=2 可以利用索引而 b=2 不能利用索引,因为 b 在全局是无序的,只有 a 确定的情况下,b 才是有序。
# 4.如何建立联合索引?
有了上面的基础,我们可以看一下关于联合索引常见的面试问题。
(1)如果 SQL 为:
SELECT * FROM table WHERE a = 1 and b = 2 and c = 3;
如果此题回答为对 (a,b,c) 建立索引,那就可以回去等通知了。
此题正确答案是任意顺序都可以, 如 (a,b,c) 或 (b,a,c) 或 (c,a,b) 都可以,重点是要将区分度高的字段放在前面,区分度低的字段放后面。像性别、状态这种字段区分度就很低,我们一般放后面。
例如假设区分度由大到小为 b,a,c。那么我们就对 (b,a,c) 建立索引。在执行 SQL 的时候,优化器会帮我们调整 WHERE 后 a,b,c 的顺序,让我们用上索引。
(2)如果 SQL 为:
SELECT * FROM table WHERE a > 1 AND b = 2;
如果此题回答为对 (a,b) 建立索引,那就可以回去等通知了。
正确答案对 (b,a) 建立索引。如果你建立的是 (a,b) 索引,那么只有 a 字段能用得上索引,毕竟最左匹配遇到范围查询就停止匹配。
如果对 (b,a) 建立索引那么两个字段都能用上,优化器会帮我们调整 WHERE 后 a,b 的顺序,让我们用上索引。
(3)如果 SQL 为:
SELECT * FROM table WHERE a > 1 and b = 2 and c > 3;
此题回答是 (b,a) 或 (b,c) 都可以,要结合具体情况具体分析。
拓展一下:
SELECT * FROM table WHERE a = 1 AND b = 2 AND c > 3;
根据最左匹配,因为字段 c 是范围查询应该放到最后,所以应该建立 (a,b,c) 或 (b,a,c)。
(4)如果 SQL 为:
SELECT * FROM table WHERE a = 1 ORDER BY b;
对 (a,b) 建索引,当 a = 1 的时候,b 相对有序,可以避免再次排序。
拓展以下,如果 SQL 为:
SELECT * FROM table WHERE a > 1 ORDER BY b;
对 (a) 建立索引,因为 a 的值是一个范围,这个范围内 b 值是无序的,没有必要对 (a,b) 建立索引。
(5)如果 SQL 为:
SELECT * FROM table WHERE a IN (1,2,3) AND b > 1;
还是对 (a, b) 建立索引,因为 IN 在这里可以视为等值引用,不会中止索引匹配,所以还是 (a,b)。
# 5.覆盖索引
覆盖索引(Covering Index)指的是一个索引包含了所有需要查询的字段,而不必回到实际的数据行中查找。当一个查询可以直接从索引中获取所有需要的信息时,就称之为覆盖索引。
-- 创建表
CREATE TABLE mytable (
col1 INT,
col2 INT,
col3 VARCHAR(255),
INDEX idx_covering (col1, col2)
);
-- 覆盖索引查询
-- 因为 idx_covering 包含了查询所需的所有列,所以是一个覆盖索引查询
SELECT col1, col2 FROM mytable WHERE col1 = 1 AND col2 = 2;
覆盖索引(Covering Index)是一种索引优化技术,旨在最小化查询开销。
联合索引有一个作用就是实现覆盖索引,如果联合索引包含了查询所需的所有列,那么查询可以直接从索引中获取所需的数据,避免了额外的表访问,这可以减少 I/O 操作,提高查询性能。
当然单列索引也可以实现覆盖索引,即查询的列是索引列。
# 参考文献
8.3.1 How MySQL Uses Indexes - MySQL (opens new window)